
Amazonセール開催中【PR】

\ 本日の掘り出し物は? /
\今、売れてるのはコレ /

ショート動画を自動編集!AIナレーション・BGM追加 Pythonスクリプト活用!
ショート動画の需要が高まる中、コンテンツ制作の効率化は多くのクリエイターや企業にとって重要な課題です。特に、複数の短い動画を組み合わせてナレーションやBGMを追加する作業は、手作業ではかなりの時間を要します。
この記事では、Python、FFmpeg、そしてAI音声合成エンジン(例: AivisSpeech Engine)を連携させ、この一連の作業を自動化するPythonスクリプトをご紹介します。一度環境を構築すれば、素材と台本を用意するだけで、簡単にオリジナルのショート動画を量産できるようになります。
この自動化で実現できること
- 素材動画のランダム結合: 用意した複数の動画クリップからランダムに指定秒数分を選び、滑らかに連結します。
- テキストからの自動ナレーション生成: テキストファイル(台本)の内容を元にAI音声合成でナレーション音声を生成し、動画に自動で付加します。
- BGMの自動選定と調整: 複数のBGMファイルからランダムに一つを選び、指定した音量で追加し、動画の終わりにフェードアウト効果を適用します。
- 出力フォーマットの統一: ショート動画に最適な縦型サイズ(1080×1920など)に自動でリサイズ・調整して出力します。
必要なもの(事前準備)
このスクリプトを実行するためには、以下のものが必要です。
- Python: スクリプトを実行する環境です。Python 3.6以上のインストールを推奨します。 Python公式ウェブサイト
- FFmpeg: 動画・音声の処理を行うためのコマンドラインツールです。スクリプトはこのFFmpegを呼び出して様々な処理を行います。お使いのOSに合わせてインストールし、「環境変数PATH」にFFmpegの実行ファイルがあるディレクトリを追加してください。正しく設定されていれば、コマンドプロンプトやターミナルで
ffmpeg -versionと入力すると情報が表示されます。 FFmpeg公式ウェブサイト - AivisSpeech Engine: テキスト音声合成を行うためのAIエンジンです。このスクリプトは、このエンジンがAPIとして特定のIPアドレスとポートで待ち受けていることを前提としています。Engineのセットアップ方法については、AivisSpeech Engineの公式ドキュメント等をご確認ください。
- Pythonライブラリ
requests: Web APIにリクエストを送るために使用します。以下のコマンドでインストールできます。 Bashpip install requests
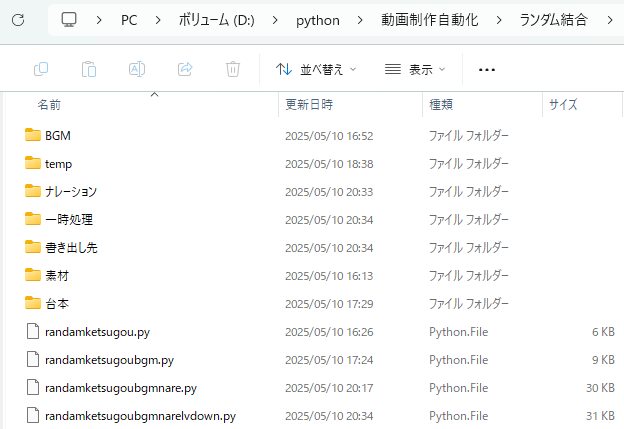
フォルダ構成の準備
スクリプトがファイルを読み書きするために、以下の図のようなフォルダ構成を推奨します。スクリプトファイルと同じ場所にこれらのフォルダを作成してください。
/あなたの作業フォルダ/
├── create_short_video.py <-- この後掲載するPythonスクリプト
├── 素材/ <-- 短い動画クリップファイル (.mp4, .avi, .movなど) を格納
├── BGM/ <-- BGMファイル (.mp3, .wavなど) を格納 (BGM不要ならフォルダは空でもOK)
├── 台本/ <-- ナレーションにしたいテキストファイル (.txt) を格納 (ナレーション不要ならフォルダは空でもOK)
├── ナレーション/ <-- 生成されたナレーション音声ファイルが一時的に保存される (スクリプトが自動作成)
├── 書き出し先/ <-- 完成した動画ファイルが保存される (スクリプトが自動作成)
└── 一時処理/ <-- FFmpeg処理のための一時ファイルが保存される (スクリプトが自動作成)
素材フォルダには、例えば1つあたり数秒〜10秒程度の短い動画ファイルを複数入れておきます。BGMフォルダには、動画の尺よりも十分長いBGM用のオーディオファイルを一つ以上入れておきます。台本フォルダには、ナレーションを読み上げさせたい内容を記述したテキストファイル(例:script_part1.txt,script_part2.txt)を入れます。これらの内容は結合されて一つのナレーションになります。文字コードはUTF-8で保存してください。
Pythonスクリプト
以下のコードをコピーし、create_short_video.py (名前は任意)として、「あなたの作業フォルダ」に保存してください。
Python
import os
import random
import subprocess
import requests
import json
import time
import traceback
# --- 設定項目 ---
AIVIS_HOST = "127.0.0.1" # AivisSpeech Engineが動作しているIPアドレス
AIVIS_PORT = "10101" # AivisSpeech Engineが動作しているポート番号
DEFAULT_SPEAKER_ID = "888753760" # 使用する話者のID (AivisSpeech Engineで利用可能なIDを確認・変更)
FFMPEG_TIMEOUT = 600 # FFmpeg処理のタイムアウト時間 (秒) - 長時間の動画処理で増やす可能性あり
# BGM関連の設定
DEFAULT_BGM_FADE_DURATION = 3 # BGMのフェードアウト時間 (秒)
DEFAULT_BGM_VOLUME = 0.3 # BGMの音量レベル (1.0が元の音量)
# フォルダパスの設定 (ご自身の環境に合わせて絶対パスで設定することを推奨)
# Windowsの場合 r"C:\Users\YourUser\Documents\VideoProject\素材" のようにパスの前に r を付けると便利です。
input_folder = r"D:\python\動画制作自動化\ランダム結合\素材" # <-- 要変更
output_folder = r"D:\python\動画制作自動化\ランダム結合\書き出し先" # <-- 要変更
bgm_folder = r"D:\python\動画制作自動化\ランダム結合\BGM" # <-- 要変更
narration_folder = r"D:\python\動画制作自動化\ランダム結合\ナレーション" # <-- 要変更 (スクリプトが自動作成も可)
script_folder = r"D:\python\動画制作自動化\ランダム結合\台本" # <-- 要変更
temp_folder = r"D:\python\動画制作自動化\ランダム結合\一時処理" # <-- 要変更 (スクリプトが自動作成も可)
# 動画の出力設定
output_base_filename="combined_video_with_audio.mp4" # 出力ファイル名のベース部分 (連番が付く)
clip_duration=3 # 各素材動画クリップを使用する長さ (秒)
final_duration=60 # ナレーションがない場合の目標動画長さ (秒)。ナレーションがある場合はナレーション長が優先されます。
width=1080 # 出力動画の幅 (ピクセル)
height=1920 # 出力動画の高さ (ピクセル)
# --- 設定項目ここまで ---
def get_media_duration(file_path):
"""
ffprobeを使ってメディアファイルの長さを取得する関数。
FFmpegのインストールとPATH設定が必要です。
"""
if not os.path.exists(file_path):
# print(f"警告: '{file_path}' が見つかりません。長さ取得をスキップします。") # 頻繁に出る可能性あるのでコメントアウト
return 0.0
try:
command = [
"ffprobe",
"-v", "error", # エラー情報のみ表示
"-show_entries", "format=duration",
"-of", "default=noprint_wrappers=1:nokey=1", # 値だけを取得
file_path
]
# 標準エラー出力も取得し、エラー原因特定に役立てる
result = subprocess.run(command, check=True, capture_output=True, text=True, encoding='utf-8', errors='ignore')
duration_str = result.stdout.strip()
if duration_str:
return float(duration_str)
else:
# print(f"警告: '{file_path}' の長さ情報がffprobeで取得できませんでした。")
# print(f"ffprobe stderr: {result.stderr.strip()}") # デバッグ時以外はコメントアウト
return 0.0
except (subprocess.CalledProcessError, ValueError, FileNotFoundError) as e:
print(f"エラー: '{file_path}' の長さ取得中にエラーが発生しました: {e}")
# traceback.print_exc() # 繰り返し表示される可能性があるのでコメントアウト
return 0.0
def generate_unique_filename(output_folder, base_filename):
"""
指定フォルダ内に既存のファイルと重複しない一意のファイル名を生成する関数。
ファイル名の最後に連番(_1, _2...)を付けます。
"""
name, ext = os.path.splitext(base_filename)
counter = 1
while True:
new_filename = f"{name}_{counter}{ext}"
output_path = os.path.join(output_folder, new_filename)
if not os.path.exists(output_path):
return new_filename
counter += 1
def text_to_speech(text, speaker_id, output_path):
"""
AivisSpeech Engine APIを使ってテキストを音声に変換する関数。
APIへのリクエストとレスポンス処理を行います。
"""
# 空白文字だけのテキストはスキップ
if not text or not text.strip():
print(f"警告: 空または空白のみのテキストのため、ナレーション生成をスキップします。")
return None
audio_query_url = f"http://{AIVIS_HOST}:{AIVIS_PORT}/audio_query"
synthesis_url = f"http://{AIVIS_HOST}:{AIVIS_PORT}/synthesis"
headers = {"Content-Type": "application/json"}
params = {"text": text, "speaker": speaker_id}
try:
# audio_query API呼び出し: テキストから音声合成のためのクエリ情報を取得
print(f"ナレーション生成: audio_query API呼び出し...")
response_query = requests.post(audio_query_url, params=params, headers=headers)
response_query.raise_for_status() # 2xx以外の場合は例外を発生させる
query_data = response_query.json()
#print(f"audio_query response: {query_data}") # デバッグ用
# synthesis API呼び出し: クエリ情報を使って音声データを生成
print(f"ナレーション生成: synthesis API呼び出し...")
response_synth = requests.post(synthesis_url, params={"speaker": speaker_id}, headers=headers,
json=query_data)
response_synth.raise_for_status() # 2xx以外の場合は例外を発生させる
# 音声ファイルの保存
with open(output_path, "wb") as f:
f.write(response_synth.content)
print(f"ナレーション生成成功: {output_path}")
return output_path
except requests.exceptions.RequestException as e:
print(f"エラー: ナレーション生成エラー (API通信失敗)")
print(f" URL: {e.request.url}")
if e.response is not None:
print(f" Status Code: {e.response.status_code}")
print(f" Response Body: {e.response.text}")
print(f" エラー詳細: {e}")
traceback.print_exc() # 詳細なトレースバックを表示
return None
except json.JSONDecodeError as e:
print(f"エラー: ナレーション生成エラー (JSONデコード失敗)")
# APIからのレスポンスボディがあれば表示
response_body = response_query.text if 'response_query' in locals() and response_query.text else 'N/A'
print(f" Response Body: {response_body}")
print(f" エラー詳細: {e}")
traceback.print_exc() # 詳細なトレースバックを表示
return None
except Exception as e:
print(f"エラー: ナレーション生成中に予期しないエラーが発生しました: {e}")
traceback.print_exc() # 詳細なトレースバックを表示
return None
def process_videos(input_folder, output_folder, bgm_folder, narration_folder, script_folder, temp_folder,
output_base_filename, clip_duration, final_duration,
width, height, bgm_fade_duration, bgm_volume):
"""
動画、BGM、ナレーションを処理して最終動画を生成するメイン関数。
"""
print("\n--- 動画処理開始 ---")
# フォルダの存在確認と作成
if not os.path.exists(input_folder):
print(f"エラー:入力フォルダ '{input_folder}' が存在しません。処理を終了します。")
return
if not os.path.exists(output_folder):
os.makedirs(output_folder)
print(f"出力フォルダ '{output_folder}' を作成しました。")
# BGMフォルダと台本フォルダはオプション
has_bgm_folder = os.path.exists(bgm_folder)
if not has_bgm_folder:
print(f"警告: BGMフォルダ '{bgm_folder}' が存在しません。BGMは追加されません。")
has_script_folder = os.path.exists(script_folder)
if not has_script_folder:
print(f"警告: 台本フォルダ '{script_folder}' が存在しません。ナレーションは追加されません。")
if not os.path.exists(narration_folder):
os.makedirs(narration_folder)
print(f"ナレーションフォルダ '{narration_folder}' を作成しました。")
if not os.path.exists(temp_folder):
os.makedirs(temp_folder)
print(f"一時フォルダ '{temp_folder}' を作成しました。")
# --- ファイルリスト取得 ---
video_files = [f for f in os.listdir(input_folder) if f.lower().endswith(('.mp4', '.avi', '.mov', '.mkv', '.webm', '.ts'))] # 対応拡張子を増やしました
bgm_files = [f for f in os.listdir(bgm_folder) if f.lower().endswith(('.mp3', '.wav', '.aac', '.flac', '.ogg'))] if has_bgm_folder else [] # 対応拡張子を増やしました
script_files = [f for f in os.listdir(script_folder) if f.lower().endswith('.txt')] if has_script_folder else []
if not video_files:
print(f"エラー:入力フォルダ '{input_folder}' に動画ファイルが見つかりませんでした。処理を終了します。")
return
# ナレーション生成 (台本がある場合のみ)
concatenated_narration_path = None # 生成された単一ナレーションファイルのパス
narration_duration = 0.0 # ナレーションの長さを初期化
if script_files:
print("\n--- ナレーション生成処理 ---")
all_script_texts = []
try:
# ファイル名順に台本ファイルを読み込み、内容を結合
script_files.sort() # ファイル名でソートして順序をある程度制御
for script_filename in script_files:
script_file_path = os.path.join(script_folder, script_filename)
with open(script_file_path, "r", encoding="utf-8") as f:
text_content = f.read().strip()
if text_content: # 空のファイルはスキップ
all_script_texts.append(text_content)
# テキストを結合。句読点や改行を調整して自然な読み上げになるように(例: 全角句点とスペースで結合)
combined_script_text = "。 ".join(text.replace('\n', ' ').strip() for text in all_script_texts if text.strip())
except Exception as e:
print(f"エラー:台本ファイルの読み込みまたは結合エラー: {e}")
traceback.print_exc()
combined_script_text = "" # エラー時はナレーション生成しない
if combined_script_text:
narration_output_filename = "combined_narration.wav" # 固定ファイル名
concatenated_narration_path_candidate = os.path.join(narration_folder, narration_output_filename)
# 既存のナレーションファイルを削除して常に新しく生成
if os.path.exists(concatenated_narration_path_candidate):
try:
os.remove(concatenated_narration_path_candidate)
print(f"既存のナレーションファイル '{concatenated_narration_path_candidate}' を削除しました。")
except OSError as e:
print(f"警告: 既存ナレーションファイル '{concatenated_narration_path_candidate}' の削除に失敗しました: {e}")
# AI音声合成APIを呼び出し
narration_path_result = text_to_speech(combined_script_text, DEFAULT_SPEAKER_ID, concatenated_narration_path_candidate)
if narration_path_result and os.path.exists(narration_path_result):
concatenated_narration_path = narration_path_result # 成功したパスをセット
# 生成されたナレーションの長さを取得
narration_duration = get_media_duration(concatenated_narration_path)
if narration_duration <= 0:
print(f"警告: 生成されたナレーションファイル '{concatenated_narration_path}' の長さが取得できないか0以下です。ナレーションは最終動画に追加されません。")
concatenated_narration_path = None # 長さが無効の場合はナレーションを使わない
else:
print(f"結合ナレーション生成完了。長さ: {narration_duration:.2f}秒")
else:
print(f"エラー: ナレーション生成に失敗しました。ナレーションは最終動画に追加されません。")
concatenated_narration_path = None # 失敗時はNoneにする
else:
print("警告: 台本ファイルが見つかりませんでした。ナレーションは追加されません。")
# 動画クリップの選択と一時ファイル作成、連結リスト生成
print("\n--- 動画クリップ処理 ---")
# 最終動画の長さに基づいて必要なクリップ数を計算
# ナレーションがある場合はその長さを基準に、ない場合は final_duration を基準にする
target_video_length = narration_duration if narration_duration > 0 else final_duration
required_clips = max(1, int(target_video_length / clip_duration)) # 少なくとも1クリップは必要
# 利用可能な動画ファイル数よりも必要なクリップ数が多い場合、警告を出す
if required_clips > len(video_files):
print(f"警告: 必要なクリップ数 ({required_clips}) が利用可能な動画ファイル数 ({len(video_files)}) より多いため、全動画ファイルを繰り返し使用します。")
# 利用可能な動画ファイルを必要な数だけ繰り返す
selected_videos = (video_files * ((required_clips // len(video_files)) + 1))[:required_clips]
else:
# 利用可能な動画ファイル数が必要なクリップ数以上の場合、ランダムに選択
selected_videos = random.sample(video_files, required_clips)
num_clips_used = len(selected_videos)
if num_clips_used == 0:
print("エラー: 使用する動画クリップを一つも選択できませんでした。処理を終了します。")
return
print(f"動画クリップを {num_clips_used} 個選択しました。")
temp_clips_list = [] # 後で一時ファイルを削除するためのリスト
concat_video_list_path = os.path.join(temp_folder, "concat_video_list.txt") # ffmpeg concat demuxer 用リスト
try:
with open(concat_video_list_path, "w", encoding="utf-8") as f:
for i, video_file in enumerate(selected_videos):
input_path = os.path.join(input_folder, video_file)
output_clip_path = os.path.join(temp_folder, f"temp_clip_{i:04d}.mp4") # ゼロ埋めしてソート順を安定させる
temp_clips_list.append(output_clip_path)
# FFmpegコマンドでクリップを切り出し、リサイズ、アスペクト比調整、音声削除
command = [
"ffmpeg",
"-y", # 上書きを許可
"-i", input_path,
"-ss", "0", # ファイルの最初から
"-t", str(clip_duration), # 指定した長さだけ切り出す
"-vf", # 映像フィルター
f"scale={width}:{height}:force_original_aspect_ratio=decrease,pad={width}:{height}:(ow-iw)/2:(oh-ih)/2,setsar=1", # 解像度調整、アスペクト比維持してパディング
"-c:v", "libx264", # 映像エンコーダー
"-preset", "ultrafast", # エンコード速度 (fastestより互換性重視)
"-crf", "23", # 画質 (0が最高、51が最低)
"-an", # 音声トラックを削除 (後でナレーション/BGMを合成するため)
"-map_metadata", "-1", # メタデータ削除
output_clip_path
]
print(f"クリップ作成: {video_file} -> {os.path.basename(output_clip_path)}")
try:
subprocess.run(command, check=True, capture_output=True, timeout=FFMPEG_TIMEOUT, text=True, encoding='utf-8', errors='ignore')
# 生成された一時クリップの存在をチェックしてから連結リストに追加
if os.path.exists(output_clip_path):
f.write(f"file '{os.path.abspath(output_clip_path)}'\n") # 絶対パスで記述
# print(f"一時クリップ生成成功: {output_clip_path}") # デバッグ用
else:
print(f"警告: クリップファイル '{output_clip_path}' の生成に失敗しました。このクリップは結合リストに含まれません。")
# 失敗した場合は削除リストからも外す
if output_clip_path in temp_clips_list:
temp_clips_list.remove(output_clip_path)
except subprocess.CalledProcessError as e:
print(f"エラー:一時ファイル作成中にエラーが発生しました: {e.stderr}")
print(f" Return Code: {e.returncode}")
traceback.print_exc()
# 重大なエラーなので処理を中断
return
except subprocess.TimeoutExpired:
print(f"エラー:一時ファイル作成処理がタイムアウトしました ({FFMPEG_TIMEOUT}秒)。処理を中断します。")
return
except Exception as e:
print(f"エラー:連結リストファイルの書き込み中にエラーが発生しました: {e}")
traceback.print_exc()
return
# 一時動画クリップの結合 (映像のみ)
print("\n--- 一時動画クリップ結合中 ---")
intermediate_video_path = os.path.join(temp_folder, "intermediate_video.mp4")
concat_command = [
"ffmpeg",
"-y", # 上書きを許可
"-f", "concat", # concat demuxer を使用
"-safe", "0", # ファイルパスのエスケープを無効化 (abspathを使っているので安全)
"-i", os.path.abspath(concat_video_list_path), # 連結リストファイルを指定
"-c", "copy", # 映像ストリームは再エンコードせずコピー
"-vsync", "vfr", # 可変フレームレートで同期 (カットによるフレーム落ち対策)
"-avoid_negative_ts", "make_zero", # タイムスタンプ負値対策
"-map_metadata", "-1", # メタデータ削除
intermediate_video_path
]
try:
# print(f"結合コマンド: {' '.join(concat_command)}") # デバッグ用
result = subprocess.run(concat_command, check=True, capture_output=True,
timeout=FFMPEG_TIMEOUT, text=True, encoding='utf-8', errors='ignore')
# FFmpegの出力は大量になることがあるので、エラー時以外はコメントアウト
# print(result.stdout)
# print(result.stderr)
if not os.path.exists(intermediate_video_path):
print(f"エラー: 中間動画ファイル '{intermediate_video_path}' の生成に失敗しました。処理を終了します。")
return # 中間動画がないと続けられないので終了
print(f"中間動画生成成功: {intermediate_video_path}")
except subprocess.CalledProcessError as e:
print(f"エラー:動画の結合中にエラーが発生しました: {e.stderr}")
print(f" Return Code: {e.returncode}")
print(f" Standard Output: {e.stdout}")
print(f" Standard Error: {e.stderr}")
traceback.print_exc()
print(f"失敗したffmpeg command: {' '.join(concat_command)}")
return
except subprocess.TimeoutExpired:
print(f"エラー:動画の結合処理がタイムアウトしました ({FFMPEG_TIMEOUT}秒)。処理を中断します。")
return
# BGMファイルを選択
bgm_file_path = None
if bgm_files:
bgm_file_path_candidate = os.path.join(bgm_folder, random.choice(bgm_files))
if os.path.exists(bgm_file_path_candidate):
bgm_file_path = bgm_file_path_candidate
print(f"BGMファイルを選択しました: {bgm_file_path}")
else:
print(f"警告: 選択したBGMファイル '{bgm_file_path_candidate}' が見つかりません。BGMは追加されません。")
else:
print("警告: BGMフォルダにファイルが見つかりませんでした。BGMは追加されません。")
# 最終的な動画結合(映像 + ナレーション + BGM)
print("\n--- 最終動画結合処理 ---")
# 最終動画の長さを決定 (ナレーション長を優先、なければ中間動画の長さ)
# Note: 映像はコピーなので、concatでできた中間動画の長さは (num_clips_used * clip_duration) に非常に近くなるはず
intermediate_video_duration = get_media_duration(intermediate_video_path)
if intermediate_video_duration <= 0:
print(f"エラー: 中間動画ファイルの長さが取得できませんでした。処理を終了します。")
return
# ナレーションがある場合はナレーション長を最終動画長とし、ナレーションがなければ中間動画の長さを採用
target_duration = narration_duration if narration_duration > 0 else intermediate_video_duration
if target_duration <= 0:
print("エラー: 最終的な動画の長さが決定できませんでした。処理を終了します。")
return
print(f"最終的な動画のターゲット長さ: {target_duration:.2f}秒")
# BGMのフェードアウト開始時間を計算
# BGMのフェードは最終動画の終端に合わせる
fade_start_time = max(0.0, target_duration - bgm_fade_duration) # 負の値にならないようにmin(0.0, ...)を使用
if bgm_fade_duration > target_duration:
print(f"警告: BGMフェードアウト時間 ({bgm_fade_duration}秒) が動画長 ({target_duration:.2f}秒) 以上です。フェードは最初から始まる可能性があります。")
# 最終的な出力ファイル名を生成
output_filename_final = generate_unique_filename(output_folder, output_base_filename)
output_path_final = os.path.join(output_folder, output_filename_final)
# FFmpeg complex filtergraph の構築
# 入力ストリームの定義とラベル付け
# 入力0: 中間動画 (映像のみ)
final_command_inputs = ["ffmpeg", "-y", "-i", intermediate_video_path]
audio_input_index_counter = 1 # 音声入力のインデックス
filter_complex_parts = [] # filter_complex オプションに渡すフィルタチェーンのリスト
amix_inputs_labels = [] # amixフィルターに渡す音声ストリームのラベルリスト
# ナレーション音声の処理チェーン
if concatenated_narration_path and os.path.exists(concatenated_narration_path):
final_command_inputs.extend(["-i", concatenated_narration_path]) # 入力1以降にナレーションを追加
nar_input_label = f"[{audio_input_index_counter}:a]" # ナレーション入力ストリームのラベル
nar_processed_label = "[nar_processed]" # 処理後のナレーションストリームのラベル
# ナレーションには特にフィルタは適用せず、ラベルだけ付けてamixへ渡す準備
filter_complex_parts.append(f"{nar_input_label}anull{nar_processed_label}") # anullでラベル付け
amix_inputs_labels.append(nar_processed_label)
audio_input_index_counter += 1
# BGM音声の処理チェーン
if bgm_file_path:
final_command_inputs.extend(["-i", bgm_file_path]) # ナレーションの次、または入力1にBGMを追加
bgm_input_label = f"[{audio_input_index_counter}:a]" # BGM入力ストリームのラベル
bgm_vol_adjusted_label = "[bgm_vol_adjusted]" # 音量調整後のBGMストリームラベル
bgm_faded_label = "[bgm_faded]" # フェードアウト後のBGMストリームラベル
# BGM入力ストリーム -> 音量調整 -> フェードアウト -> ラベル付け
filter_complex_parts.append(f"{bgm_input_label}volume=volume={bgm_volume}{bgm_vol_adjusted_label}")
filter_complex_parts.append(f"{bgm_vol_adjusted_label}afade=type=out:st={fade_start_time}:d={bgm_fade_duration}{bgm_faded_label}")
amix_inputs_labels.append(bgm_faded_label) # amixにはフェード後のBGMストリームを渡す
audio_input_index_counter += 1
# 音声ストリームのミキシング (amix) または単一ストリームの出力
audio_map_output_label = None # 最終的な音声出力ストリームのラベル
num_audio_inputs_to_mix = len(amix_inputs_labels)
if num_audio_inputs_to_mix > 1:
# 複数の音声入力がある場合、amixフィルターで結合
amix_output_label = "[aout]"
# amixフィルターチェーン: [音声1ラベル][音声2ラベル]...amix=inputs=N:duration=shortest[出力ラベル]
amix_filter_chain = f"{''.join(amix_inputs_labels)}amix=inputs={num_audio_inputs_to_mix}:duration=shortest{amix_output_label}"
filter_complex_parts.append(amix_filter_chain) # amixフィルターチェーンをフィルタグラフに追加
audio_map_output_label = amix_output_label # 最終的な音声はamixの出力ストリームをマップ
elif num_audio_inputs_to_mix == 1:
# 音声入力が1つの場合、amixは不要。その単一ストリームを最終出力としてマップ。
single_audio_stream_label = amix_inputs_labels[0] # 例えば '[nar_processed]' または '[bgm_faded]'
audio_map_output_label = single_audio_stream_label # そのまま最終出力としてマップ
# filter_complex オプション文字列を生成 (フィルターチェーンが存在する場合のみ)
filter_complex_string = ";".join(filter_complex_parts) if filter_complex_parts else None
# 最終的なFFmpegコマンドの構築
final_command = final_command_inputs
# フィルタグラフを追加 (フィルターチェーンが存在する場合のみ)
if filter_complex_string:
final_command.extend(["-filter_complex", filter_complex_string])
# ストリームのマッピング
final_command.extend(["-map", "0:v"]) # 必ず中間動画の映像ストリーム (入力0) をマップ
# 音声ストリームをマップ (音声がある場合)
if audio_map_output_label is not None:
final_command.extend(["-map", audio_map_output_label]) # amixの出力 or 単一音声ストリームをマップ
else:
final_command.extend(["-an"]) # 音声トラックがない場合は音声なしオプションを追加
# 出力時間の指定 (ナレーション長 or 目標動画長)
final_command.extend(["-t", str(target_duration)])
# その他出力オプション
final_command.extend([
"-c:v", "copy", # 映像は中間動画からそのままコピー (再エンコードしないため高速・高画質)
"-c:a", "aac", "-ac", "2", # 音声はAACステレオでエンコード (互換性のため)
"-movflags", "+faststart", # Web再生向けに最適化
"-map_metadata", "-1", # メタデータ削除
output_path_final,
])
try:
print(f"\n実行するFFmpegコマンド:\n{' '.join(final_command)}\n")
# FFmpegの標準出力を表示して進捗を確認しやすくする (大量に出る場合あり)
result = subprocess.run(final_command, check=True, capture_output=True,
timeout=FFMPEG_TIMEOUT, text=True, encoding='utf-8', errors='ignore')
print("--- FFmpeg標準出力 ---")
print(result.stdout)
print("--- FFmpeg標準エラー出力 ---")
print(result.stderr)
print("------------------------")
if os.path.exists(output_path_final) and get_media_duration(output_path_final) > 0:
print(f"動画処理成功!出力ファイル: {output_path_final}")
else:
print(f"エラー: 最終出力ファイル '{output_path_final}' が正常に生成されていないようです。FFmpegのエラー出力を確認してください。")
except subprocess.CalledProcessError as e:
print(f"\nエラー:FFmpegコマンド実行中にエラーが発生しました。")
print(f" Return Code: {e.returncode}")
print(f" Standard Output:\n{e.stdout}")
print(f" Standard Error:\n{e.stderr}")
traceback.print_exc()
print(f"\n失敗したコマンド: {' '.join(final_command)}")
except subprocess.TimeoutExpired:
print(f"\nエラー:FFmpegコマンド実行がタイムアウトしました ({FFMPEG_TIMEOUT}秒)。処理を中断します。")
except Exception as e:
print(f"\n予期しないエラーが発生しました: {e}")
traceback.print_exc()
finally:
# --- 一時ファイルのクリーンアップ ---
print("\n--- 一時ファイルをクリーンアップ中 ---")
# 動画連結用リストファイル
if 'concat_video_list_path' in locals() and os.path.exists(concat_video_list_path):
try:
os.remove(concat_video_list_path)
print(f"削除: {concat_video_list_path}")
except OSError as e:
print(f"エラー: ファイル '{concat_video_list_path}' の削除に失敗しました: {e}")
# 一時動画クリップファイル
# temp_clips_list に含まれていても、実際にファイルが生成されなかった可能性があるので os.path.exists で確認
for temp_clip in temp_clips_list:
if os.path.exists(temp_clip):
try:
os.remove(temp_clip)
print(f"削除: {temp_clip}")
except OSError as e:
print(f"エラー: ファイル '{temp_clip}' の削除に失敗しました: {e}")
# 中間動画ファイル
if 'intermediate_video_path' in locals() and os.path.exists(intermediate_video_path):
try:
os.remove(intermediate_video_path)
print(f"削除: {intermediate_video_path}")
except OSError as e:
print(f"エラー: ファイル '{intermediate_video_path}' の削除に失敗しました: {e}")
# 結合されたナレーションファイル
if 'concatenated_narration_path' in locals() and concatenated_narration_path and os.path.exists(concatenated_narration_path):
try:
os.remove(concatenated_narration_path)
print(f"削除: {concatenated_narration_path}")
except OSError as e:
print(f"エラー: ファイル '{concatenated_narration_path}' の削除に失敗しました: {e}")
print("\n--- 動画処理終了 ---")
# スクリプトを直接実行した場合に process_videos 関数を呼び出す部分
if __name__ == "__main__":
# ここで各設定変数を指定して関数を呼び出します
# スクリプト冒頭の設定値をそのまま使うか、ここで個別に指定できます。
# ここで指定した値は冒頭の設定値より優先されます。
print("スクリプトが直接実行されました。process_videos関数を開始します。")
# === ここにあなたのフォルダパスを設定してください ===
# 例:
# base_dir = r"C:\Users\YourUser\Documents\AutoVideo"
# input_folder_path = os.path.join(base_dir, "素材")
# output_folder_path = os.path.join(base_dir, "書き出し先")
# bgm_folder_path = os.path.join(base_dir, "BGM")
# narration_folder_path = os.path.join(base_dir, "ナレーション")
# script_folder_path = os.path.join(base_dir, "台本")
# temp_folder_path = os.path.join(base_dir, "一時処理")
# === 上記を参考に、実際のフォルダパスに合わせて修正してください ===
# !!! 注意 !!!
# 以下のパスはあくまで例です。ご自身の環境に合わせて上の例のように必ず書き換えてください。
configured_input_folder = r"D:\python\動画制作自動化\ランダム結合\素材"
configured_output_folder = r"D:\python\動画制作自動化\ランダム結合\書き出し先"
configured_bgm_folder = r"D:\python\動画制作自動化\ランダム結合\BGM"
configured_narration_folder = r"D:\python\動画制作自動化\ランダム結合\ナレーション"
configured_script_folder = r"D:\python\動画制作自動化\ランダム結合\台本"
configured_temp_folder = r"D:\python\動画制作自動化\ランダム結合\一時処理"
process_videos(
input_folder=configured_input_folder,
output_folder=configured_output_folder,
bgm_folder=configured_bgm_folder,
narration_folder=configured_narration_folder,
script_folder=configured_script_folder,
temp_folder=configured_temp_folder,
output_base_filename="my_generated_short.mp4", # 出力ファイル名ベース
clip_duration=4, # 各クリップ4秒
final_duration=60, # ナレーションがない場合60秒目標
width=1080, # 幅1080px
height=1920, # 高さ1920px (縦動画)
bgm_fade_duration=4, # BGMフェードアウト4秒
bgm_volume=0.2 # BGM音量0.2倍
# DEFAULT_SPEAKER_ID は process_videos 関数内で使われるため、
# 冒頭のグローバル変数を変更してください。
)
スクリプトの設定変更
コードの冒頭にある以下の部分で、動作設定やフォルダパスを指定します。ご自身の環境や目的に合わせて、必ずこの部分を編集してください。
Python
# --- 設定項目 ---
AIVIS_HOST = "127.0.0.1" # AivisSpeech Engineが動作しているIPアドレス
AIVIS_PORT = "10101" # AivisSpeech Engineが動作しているポート番号
DEFAULT_SPEAKER_ID = "888753760" # 使用する話者のID (AivisSpeech Engineで利用可能なIDを確認・変更)
FFMPEG_TIMEOUT = 600 # FFmpeg処理のタイムアウト時間 (秒)
# BGM関連の設定
DEFAULT_BGM_FADE_DURATION = 3 # BGMのフェードアウト時間 (秒)
DEFAULT_BGM_VOLUME = 0.3 # BGMの音量レベル (1.0が元の音量)
# フォルダパスの設定 (ご自身の環境に合わせて絶対パスで設定することを推奨)
# Windowsの場合 r"C:\Users\YourUser\Documents\VideoProject\素材" のようにパスの前に r を付けると便利です。
input_folder = r"D:\python\動画制作自動化\ランダム結合\素材" # <-- 要変更
output_folder = r"D:\python\動画制作自動化\ランダム結合\書き出し先" # <-- 要変更
bgm_folder = r"D:\python\動画制作自動化\ランダム結合\BGM" # <-- 要変更
narration_folder = r"D:\python\動画制作自動化\ランダム結合\ナレーション" # <-- 要変更
script_folder = r"D:\python\動画制作自動化\ランダム結合\台本" # <-- 要変更
temp_folder = r"D:\python\動画制作自動化\ランダム結合\一時処理" # <-- 要変更
# 動画の出力設定
output_base_filename="combined_video_with_audio.mp4" # 出力ファイル名のベース部分 (連番が付く)
clip_duration=3 # 各素材動画クリップを使用する長さ (秒)
final_duration=60 # ナレーションがない場合の目標動画長さ (秒)。ナレーションがある場合はナレーション長が優先されます。
width=1080 # 出力動画の幅 (ピクセル)
height=1920 # 出力動画の高さ (ピクセル)
# --- 設定項目ここまで ---
特にフォルダパスは、必ずご自身の環境に合わせて書き換えてください。
また、スクリプトの最後(if __name__ == "__main__": のブロック)でも、process_videos 関数を呼び出す際に引数としてこれらの設定値を渡しています。ここで値を指定した場合、スクリプト冒頭のデフォルト設定よりも優先されます。複数のパターンを試したい場合は、この部分を編集すると便利です。
Python
if __name__ == "__main__":
print("スクリプトが直接実行されました。process_videos関数を開始します。")
# === ここにあなたのフォルダパスを設定してください ===
# ... (上記コードと同じパス設定の例)
configured_input_folder = r"D:\python\動画制作自動化\ランダム結合\素材" # <-- 実際のパスに修正
configured_output_folder = r"D:\python\動画制作自動化\ランダム結合\書き出し先" # <-- 実際のパスに修正
configured_bgm_folder = r"D:\python\動画制作自動化\ランダム結合\BGM" # <-- 実際のパスに修正
configured_narration_folder = r"D:\python\動画制作自動化\ランダム結合\ナレーション" # <-- 実際のパスに修正
configured_script_folder = r"D:\python\動画制作自動化\ランダム結合\台本" # <-- 実際のパスに修正
configured_temp_folder = r"D:\python\動画制作自動化\ランダム結合\一時処理" # <-- 実際のパスに修正
process_videos(
input_folder=configured_input_folder,
output_folder=configured_output_folder,
bgm_folder=configured_bgm_folder,
narration_folder=configured_narration_folder,
script_folder=configured_script_folder,
temp_folder=configured_temp_folder,
output_base_filename="my_generated_short.mp4", # <-- ここで個別に設定可能
clip_duration=4, # <-- ここで個別に設定可能
final_duration=60, # <-- ここで個別に設定可能
width=1080, # <-- ここで個別に設定可能
height=1920, # <-- ここで個別に設定可能
bgm_fade_duration=4, # <-- ここで個別に設定可能
bgm_volume=0.2 # <-- ここで個別に設定可能
# DEFAULT_SPEAKER_ID は process_videos 関数内で使われるため、
# 冒頭のグローバル変数を変更してください。
)
スクリプトの実行方法
設定が終わったら、コマンドプロンプトまたはターミナルを開き、create_short_video.py を保存したディレクトリに移動します。
Bash
cd /あなたの作業フォルダへのパス/
そして、以下のコマンドを実行します。
Bash
python create_short_video.py
スクリプトが実行され、コンソールに処理の進捗状況やエラーメッセージが表示されます。
処理の簡単な流れ
- 設定されたフォルダが存在するか確認し、必要なら作成します。
台本フォルダに.txtファイルがあれば、それらの内容を全て読み込み、結合して一つの長いテキストにします。- 結合したテキストをAivisSpeech EngineのAPIに送信し、ナレーション音声ファイル(
.wav)を生成してナレーションフォルダに保存します。 - ナレーションが生成された場合、その音声の長さが最終的な動画の長さの基準となります。ナレーションがない場合は、
final_durationで指定した時間が基準になります。 - 最終動画の長さに応じて、
素材フォルダから必要な数の動画ファイルをランダムに選択します。 - 選択した各動画ファイルから、
clip_durationで指定した長さのクリップを切り出し、widthxheightのサイズにリサイズ・調整(アスペクト比を維持しつつ余白を追加)、そして元の音声を削除した一時動画ファイルを作成し、一時処理フォルダに保存します。 - 作成した一時動画ファイルをFFmpegの
concat機能を使って連結し、映像のみの中間動画を作成します。 BGMフォルダにファイルがあれば、そこから一つをランダムに選択します。- 中間動画(映像)、生成されたナレーション音声(もしあれば)、選択されたBGM(もしあれば)を、FFmpegの複雑なフィルタグラフを使って結合します。この際、BGMの音量調整やフェードアウト処理も同時に行います。
- 完成した動画ファイルを
書き出し先フォルダに保存します。ファイル名はoutput_base_filenameに連番が付加されたものになります。 - 処理中に生成された一時ファイル(一時動画クリップ、中間動画、連結リストファイル、生成ナレーション)を自動的に削除します。
カスタマイズのポイント
- ナレーション内容:
台本フォルダ内の.txtファイルを編集することで、ナレーションの内容を自由に変更できます。ファイルの先頭から順に結合されるため、ファイル名の付け方(例:01_intro.txt,02_body.txt)で読み上げ順を制御できます。 - 使用する動画クリップ:
素材フォルダに入れる動画ファイルを変更することで、生成される動画の雰囲気を変えられます。短い、多様な動画を用意すると、ランダム性が活かせます。 - 動画の尺と構成:
clip_duration(個々のクリップ長) とfinal_duration(目標動画長) を調整することで、動画全体の長さを制御できます。ただし、ナレーションがある場合はナレーション長が優先される点に注意してください。 - デザイン:
widthとheightで出力動画の解像度を設定します。縦型ショート動画以外にも、横型動画 (width=1920, height=1080) としても利用可能です。 - BGM:
BGMフォルダに複数のファイルを入れておけば、実行ごとにランダムに選ばれます。DEFAULT_BGM_VOLUMEでBGMの音量を、DEFAULT_BGM_FADE_DURATIONで終端のフェードアウト時間を調整できます。
うまくいかないときは(トラブルシューティング)
- FFmpegエラー: コマンドプロンプト/ターミナルに表示されるFFmpegのエラーメッセージ(特に
Standard Errorの部分)をよく確認してください。入力ファイルの問題、フィルタオプションの記述ミス、FFmpegのインストール状態などが原因として考えられます。 - API接続エラー: 「API通信失敗」などのエラーが出る場合、
AIVIS_HOSTやAIVIS_PORTがAivisSpeech Engineの実際の設定と合っているか確認してください。また、Engineが正常に起動しているかも確認が必要です。ネットワークやファイアウォールの設定も影響することがあります。 - ファイル/フォルダが見つかりませんエラー: スクリプト内のフォルダパス設定が正しいか、大文字・小文字も含めて確認してください。また、指定したフォルダに素材ファイルがきちんと格納されているか確認してください。
- ナレーションが生成されない:
台本フォルダに.txtファイルがあるか、ファイル内容が空でないか確認してください。また、API接続が正常かも確認が必要です。 - 動画の長さがおかしい: ナレーションがある場合はナレーション長が優先されます。想定したナレーション長になっているか確認してください。
まとめ
このPythonスクリプトと関連ツールを組み合わせることで、ショート動画の大量生産プロセスを効率化できます。ランダム性を取り入れつつ、ナレーションやBGMも自動で付加するため、様々なバリエーションの動画を簡単に生成できます。
ぜひこの自動化スクリプトを活用して、あなたの動画コンテンツ制作の幅を広げてください!
